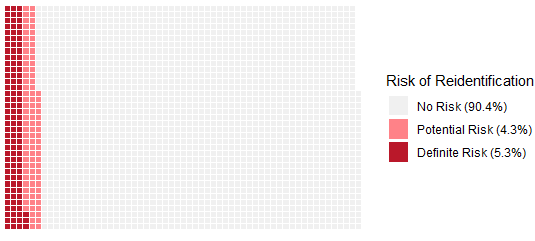Protecting Privacy in the Era of Open Science
We just published our findings and recommendations for researchers to better protect the privacy of research participants when sharing open data. Examining over 2,000 public datasets from papers using human participants, we found that 5-10% contained information that could potentially re-identify participants.
Furthermore, half of those datasets contained data touching on sensitive topics. We propose several practical recommendations that researchers should implement to safeguard their datasets from such liabilities before sharing them.
The paper is published at Nature Human Behavior and we’ve also released a pre-print with more detail about our methods. I presented some preliminary findings at the MetaScience Conference back in 2021 (video link).