As a side project, I wrote some code to automatically pull my data from the Strava API and visualize it with some cool R packages. I documented the code on GitHub so that anyone can do this with their own Strava data.
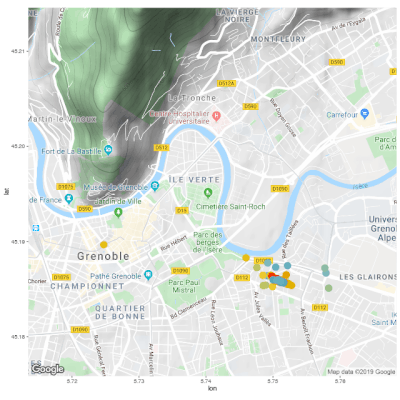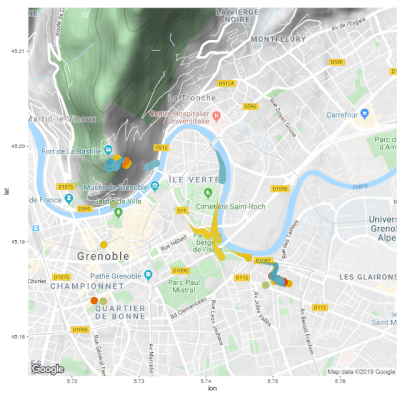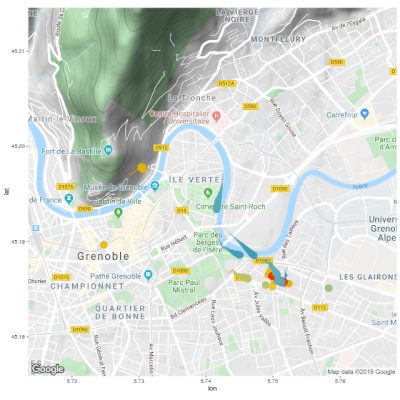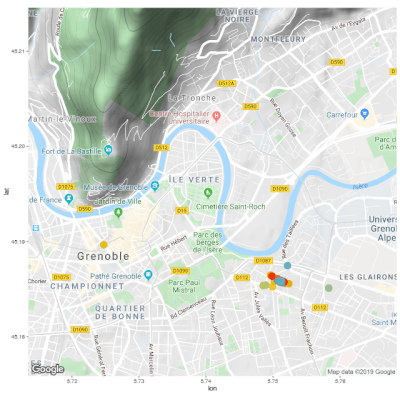
As a side project, I wrote some code to automatically pull my data from the Strava API and visualize it with some cool R packages. I documented the code on GitHub so that anyone can do this with their own Strava data.
Our prior work demonstrated that 5-10% of open datasets contain potential privacy violations, so we developed a tool to help. DataCheck can automatically scan a dataset and flag 14 types of common privacy violations before a researcher makes their data public. Available as both a Web app and R package, the tool runs locally so there is no risk of exposing participant data during the scan. It was validated on both live and simulated datasets to be >98% accurate.
We just published our findings and recommendations for researchers to better protect the privacy of research participants when sharing open data. Examining over 2,000 public datasets from papers using human participants, we found that 5-10% contained information that could potentially re-identify participants.
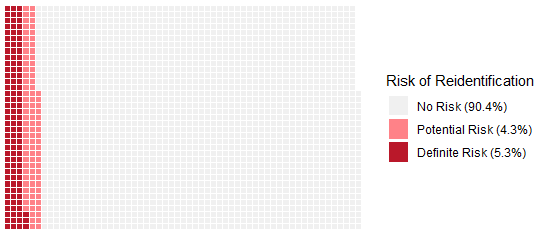
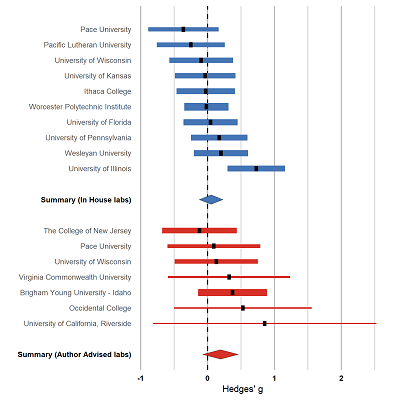
We released Many Labs 4 open access in Collabra: Psychology. We also wrote a brief summary post for the COS blog. You can follow some discussion on Twitter here or here.
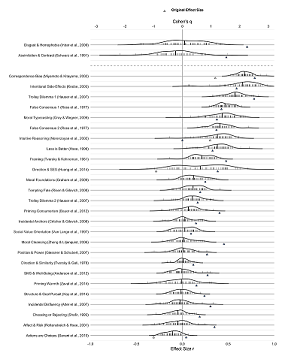
EDIT: ML2 was published Dec 2018, open access in AMPPS. See also the commentaries from original authors.
ORIGINAL: The Many Labs 2 project has been submitted and is under review at AMPPS. Overall, 28 psychology studies were replicated across >120 samples from 34 countries around the world, totaling >15,000 participants.
Public release of the results/manuscript/data should occur shortly, pending final revisions and alongside commentaries from original authors.
This website is built using the ‘blogdown’ R package, uploaded to a GitHub repo, then served to web with Netlify. Credit to the Hugo Tranquilpeak theme.
One advantage is that we can write in simple R Markdown, and embed+run R code easily:
